What does high quality data look like?
There has been a dramatic increase in the quantity, variety, and complexity of data stored and shared across public and private domains. Annual global data generation is projected to exceed 163 zettabytes (ZB) by 2025, a 10-fold increase from where it stood in 20161. With this comes an uptick in data complexity, as unstructured, low latency forms of data (e.g., dynamic data, digital assets) are becoming increasingly central for firm across all industries to remain competitive.
This recent data boom has largely been praised, as mass quantities of data can be used to provide firms with greater insight into company performance, customer service quality, and operational efficiency; however, not all data is created equal. Complex forms of information, or data in excess, can produce the opposite of its intended effect by clouding a firm’s ability to lay out a clear strategic vision. Notably, although data is now widely available, managers often feel their data is not nuanced, is incomplete, or is even simply inaccurate. This reduces confidence and increases the likelihood of inadvertently misappropriating data that can be damaging to businesses – financially or otherwise.
In short, large portions of the data used by businesses today are low quality. To enable firms to truly get the greatest benefits out of their enterprise data, they must ensure use of “high quality data,” namely data that is consistent, accessible, accurate, relevant, and complete.
The prevalence of low-quality data today is largely attributable to data becoming increasingly decentralized, as well as to a lack of data lineage tracing. While centralized data repositories are primed for high security and control, it is difficult to monitor where decentralized data is stored, who has access to it, who is making copies, and how it is being used. There has been a marked shift from the uptake of enterprise business intelligence platforms, centrally managed by IT departments, to the use of self-service and data service tools. Self-service tools increase the agility of the individual business users and lower barriers to entry for the use of data and generation of insights; however, they often result in the use of unverified or low-quality data to create dashboards. Without adequate governance in place, data will be freely replicated, increasing the overall quantity of data in circulation, and ultimately the demand for more infrastructure capacity data management, as users attempt to address the incompleteness and dissonance of their data repositories. Until this feedback loop is addressed through proper means of control, processes, and automation, such as data lineage tracing and replication restrictions, this problem will grow and exacerbate existing complexity.
Rapid innovation is accelerating the problem of data decentralization and data complexity. AI sensors, IoT, and robots all collect and produce vast amounts of data. As these technologies become more accessible, they have led to a stark increase in the overall data flow.
Businesses can leverage a centralized data repository, in the form of a data lake, to store structured and unstructured data, including relational and non relational data from internal and external corporate applications. Companies who implemented a data lake experienced a 9% organic revenue growth.2 The ability to successfully generate business value from vast quantities of data differentiates businesses from their competition. Still, implementing a data lake solution or enhancing data warehousing capabilities requires a holistic data governance strategy to maintain, manage, and protect the ever-growing volumes of data, while meeting regulatory requirements and adequately addressing data needs across the organization.
Exhibit 1. Need for Robust Data Governance
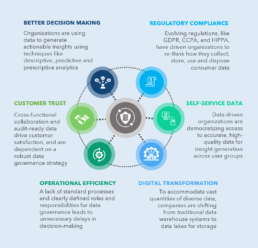
Consequences of Mis- or Un-managed Data
The increasing use and complexity of data today poses a significant security threat to firms as well. Inadequate approaches for identity and access management have permitted the development of insecure data interfaces, thereby leading to increased rates of security breaches, data loss, and system failures.
In 2019, a Facebook data breach exposed over 533 million users’ information to the public internet, resulting in a $5 billion class action lawsuit against the firm.3 Considering that a significant quantity of data is employee and customer personally identifiable Information (PII), the consequence of inadvertently losing or releasing this data into the wrong hands is particularly damaging from both an ethical and legal standpoint. As shown through the 2019 Facebook data breach, the financial burden of mis-handled data can also be severe. IP leaks through theft or inadvertent disclosure can cost millions of dollars, loss of market share, loss of shareholder value, and negative publicity.4 Additionally, large amounts of electronically stored information demand higher storage costs. Specifically, poor data quality leads to an average of $15 million in yearly losses for firms.5 Similarly, as regulators and legal entities tighten their stance on data management practice standards, the threat of lawsuits and legal penalties is high for firms who fail to meet compliance standards. The European Central Bank’s Data Quality Dashboard, California Consumer Privacy Act (CCPA), and EU General Data Protection Regulation (GDPR), are only a few of numerous recent amendments to data privacy standards laid out by major regulatory bodies over the last several years. Failure to meet these standards almost always results in costly fines and legal fees, while simultaneously preoccupying limited application development capacity, thus slowing time to market for other initiatives.6
Additionally, an absence of mature data governance best practices will result in an inefficient use of time and resources. Data processing and clean-up consume time and increase frustration among business analyst and data scientist alike: Approximately 30% of employee time today is spent on non-value-add tasks, primary driven by lack of standardization, poor data quality, and limited availability.7
Non-user-friendly data management systems and ineffective governance rules are often circumvented by employees through individual storage and underground archiving, including through the creation of data silos. This hinders employees’ productivity in the long-term and increases the chances of human error, when retained data cannot be found.
Maximizing Data Utility
Despite the risks and challenges associated with the current state of data usage, there are clear opportunities for improvement. Data value assessments can reduce quantity and complexity.
Only ~30% of data stored by firms is in active, continuous use: on average, ~1% of data is on hold in litigation, 5% is required for record retention, and 25% has legitimate current business value. Therefore, ~70% percent of data can or should be deleted.8 Not only is most data likely invaluable, but the relative utility of data drops significantly with time, as a mere ~1% of data is reused after 15 days. Both these findings suggest that data should be examined critically and frequently to assess whether the functional utility of that data outweighs the risk of storing it.
Determining whether data is valuable may seem like an obscure and iterative task but defining and quantifying specific value creation criteria can streamline this process. Indeed, directional goals, such as “ensure effective use of customer of data” are not precisely quantifiable, and therefore difficult to track. Only through leveraging expressive key performance indicators (KPIs) is it possible to conduct an unbiased assessment of whether outcomes are satisfactory and lay out a prescriptive path for change. These KPIs can be customized to most closely reflect a given facet of data quality, but the goal is always to create an objective metric with a clear interpretation. Once the pitfalls of a data ecosystem are revealed, it becomes easier to act and establish governance procedures around critical areas.
KPIs can also be used to assess the effectiveness of a data governance system that is already in place. Most broadly speaking, data quality and governance KPIs can be categorized into three primary categories: 1) efficiency metrics, which track how a data governance program helps improve the effectiveness a firm, 2) enablement metrics, which highlight new opportunities created for an institution through the installment of a data governance program, and 3) enforcement metrics, which illustrate how data governance programs help impose corporate mandates and the corresponding standards.
Exhibit 2. KPIs for Data Quality & Governance
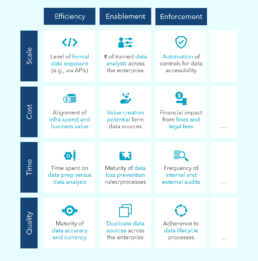
One example of a metric that can be quantitatively validated to assess the overall health of a data governance system is the level of data liquidity. Data liquidity is defined as the ability to get data from its point of origin to its many points of use efficiently and is arguably the most informative marker of a thriving data governance structure. Leveraging metadata — descriptive information about the structure and content of data — can also help to identify where there is a particular need for data governance, facilitating recognition of the original source.9 Areas where data has been moved and copied can be more easily identified, while also suggesting to designated source of that data in the first place. In addition, establishing this transparency and driving remediation can yield significant cost savings, given the often-times non-linear scaling of resource requirements for core ERP systems.
An effective data governance strategy must directly address these types of metrics. For example, through data quality management and metadata management, enterprises can decontextualize data from a designated purpose and prepare each asset to be accurate and standardized, allowing for large amounts of data to be available in real-time for use across the organization.10
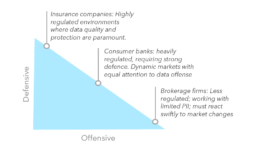
The next consideration pertains to balance: when it comes to defining and instating a data governance strategy, companies must find the appropriate balance of “defensive” and “offensive” approaches.
Defensive data strategies are those in which the objective is to safeguard data security, privacy, integrity, quality, regulatory compliance, and governance. Firms can achieve this through optimization of data extraction, standardization, storage, and access – activities, centered around increasing the overall level of control. Conversely, offensive data strategies are those that aim to improve competitive positioning and profitability through data analytics, as well as through data enrichment and transformation. These types of activities tend to directly target data liquidity, increasing the inherent level of flexibility in data and therefore reducing the need for data decentralization. The direction that a company takes in being more defensive or offensive, depends on a company’s scope of business, which include the regulatory environment and industry competition.
Exhibit 3. The Data Strategy Spectrum
How Kepler Can Help
The process of designing a tailored data governance system is not trivial. Businesses must establish a clear approach for measuring progress: objective data governance goals with a roadmap containing incremental targets and clear timelines.
KPIs must also be defined to track the success of the overall strategy and validate the objectivity of proposed targets. Fortunately, through leveraging Kepler Cannon’s robust experience in data management and analytics, an effective and efficient system of change can be laid out, taking into consideration the multitude of lessons learned from previous engagements. Specifically, Kepler’s data governance frameworks focused on data quality, access, and distribution, provide clients with a custom-blueprint and delivery approach for enacting a scalable governance system based on a company’s unique needs and functional priorities. These frameworks include a comprehensive set of pre-defined, industry standard KPIs and can help to accelerate the creation of a robust governance approach.
As a first step, we propose a three-pillar data-governance model with clear responsibilities and interactions between systems operating jointly under a data governance council. The responsibility of the council is to continuously review the data-related processes and KPIs, in order to evaluate the data governance program’s effectiveness.
For this, a data strategy team is elected to assess the unique needs of a business. As the scope of initiatives within a business evolves, so too will the need for data. This can be impacted by external, including regulatory factors, as well as by internal drivers, such as new product launches and acquisitional growth. These developments have a major effect on who within an organization needs data and how it will be used. This team must therefore constantly reassess the current state of an organization and define an actionable vision for a thriving data governance system.
Exhibit 4. Security Council-based Governance
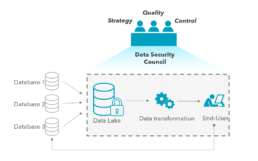
Second, a data quality team is launched to instate systems of oversight and a cadence of formalized series of review. These should include:
- enactment of data quality score cards,
- data lineage tracing,
- data categorization,
- and formalization of KPIs for respective data categories.
This in turn creates both a method for assessment, as well as a system for flagging high risk data practices and data types.
Third, a technically focused data control team will work to limit misuse of data through data replication blocking, setup of central data repositories, customizable control features, and data transformation initiatives. Once the data governance model has been established, the business must continue to monitor and track data metrics and benchmark the process capabilities against a defined maturity model. The above-mentioned efficiency, enablement, and enforcement metrics must be measured to gauge the effectiveness of the performance and execution, as well as whether data needs are being met continuously across the entire organization.
Ongoing maturity assessment of the in-flight data governance model, on the staged scale, i.e., from level 1 (initial) to level 5 (optimizing), will enable the creation of a long-term data governance roadmap and allow your business to focus attention on specific areas where actionable opportunities can be addressed rapidly.
Exhibit 5. Data Quality and Maturity Scorecards
In Closing...
The potential use cases for data assets are increasing at an exponential rate. However, collecting and storing data is only one part of the equation. Mismanaged data poses significant consequences for firms, increasing storage costs and time spent on data preparation, as well as the risk of cybersecurity incidents and system failures.
To guarantee scalability, firms must establish a disciplined approach to data governance. They need to be able to extract more prescriptive insights from their data, while reducing maintenance costs. This also helps reduce risk and secure a competitive advantage.
Developing and instating an adaptable model for data governance is not an easy feat. Kepler Cannon’s dynamic governance models leverage repositories of descriptive KPIs to ensure that businesses leverage the highest quality data and secure effective controls.
As compliance and businesses require better information for speedier decisions, data governance should be the primary area of focus to capture and reap long term benefits of a functional, efficient, and dynamic data environment.
__________________________________________________________________________________________________________
1. Barford, C., Wallance, S., Shahapurkar, M., Liver, J., Saidenberg, M. & Goyne, E. (2020).
2. Lock, M. (2017). Angling For Insight In Today’s Data Lake. Aberdeen.
3. Sohail, O., Sharma, P., & Ciric, B. (2018). Data Governance for Next-Generation Platforms. Deloitte.
4. Micro Focus. (2017). Information Governance – Challenges and Solutions.
5. Moore, S. (2018). How to Create a Business Case for Data Quality Improvement. Gartner.
6. Baltassis, E., Gourévitch, A., & Quarta, L. (2019). Good Data Starts with Great Governance. BCG.
7. Petzold, B., Roggendorf, M., Rowshankish, K., & Sporleder, C. (2020).
8. Compliance, Governance and Oversight Counsel (CGOC) Summit. (2012).
9. Sohail, O., Sharma, P., & Ciric, B. (2018). Data Governance for Next-Generation Platforms. Deloitte.
10. Sundararajan, A. & Sonderegger, P. (2020). The Hidden Data Economy. Oracle + ADAPT.
Read More

The Open Book on Compliance – US Open Banking Regulations Decoded
The CFPB’s new Open Banking regulations will impact how financial service providers can access and monetize consumer data, while also influencing future practices around security, consent, and data sharing.

Mixed Reality
As these technologies become more accessible to the wider public, AR and VR are expected to grow into a $125 billion market by 2025.

Money Games
The use of gamification has proliferated across all industries, with retail, entertainment and education leading the charge. Apps like Duo Lingo, Kahoot, Fitbit, Starbucks etc., are all some of the most prevalent examples.

Monetizing Data Analytics
For several years, it has been said that “data is the new oil” and arguably, the most valuable strategic asset for a business. Whilst getting value out of data might be less straight-forward, it is true that data needs to be refined to make it valuable.

From Cards to Chains – Payments in the Blockchain Era
To remain competitive in the evolving financial landscape, card networks are uniquely positioned to bridge this gap between traditional payments and new blockchain networks as transaction facilitators, leveraging their global reach to make transactions on their networks quicker, cheaper, and more secure.

A Borderless World
Significant shifts are underway in the cross-border payments sector, across the demand-side and supply-side. Consumer expectations from domestic payments (instant, fully traceable, risk-free, etc.) are being applied to the more complex cross-border space. Businesses that capitalize on these shifts stand to shape the future of the industry.

Cracking the FedNow Code
Real-time payments are increasingly recognized as a critical component of modern financial systems, offering speed and convenience in an interconnected digital world. As we venture into the future, the recent launch of the Federal Reserve's instant payment service, FedNow, stands at the forefront of a payment revolution in the US.

Future-Proofing Healthcare Delivery
The right telehealth platform is critical to meeting patient expectations and providing the best possible provider, patient and administrator experience. Today patients are demanding more control over their healthcare and want to access care from anywhere.

The GenZ Wave
Gen Z is not merely a younger version of millennials; they are poised to disrupt all aspects of the economy. Companies must therefore adapt in time to cater to the preferences and expectations.

Gaming and Financial Services
As younger generations start to play for competition and skill development, there is a rise in payment flows, volumes, and subsequent opportunities arising out of the same. Financial institutions are not only presented with the opportunity to monetize on gamers but also target younger Gen Z and Millennial consumers to upsell and cross-sell their existing products.

Maximizing Value from Value Added Resellers
The role of Value Added Resellers (VARs) is transforming from basic reselling to strategic technology partnerships that offer comprehensive IT solutions. To maximize the value of these evolving relationships, firms must bring transparency to pricing, agreements, and the scope of work.

Latent Growth in LatAm Credit Cards
The payments industry has been experiencing explosive growth across Latin America over the past few years: cash usage has decreased ~20% as consumers pivoted towards payment products that are well integrated into the financial ecosystem.

Navigating the Buy Now Pay Later Era
The rising aspirations of consumers combined with the limited access to, and opaque nature of traditional financing solutions, has given rise to innovative products for underserved segments. BNPL is one such solution that offers short-term financing to users with the ability to pay in definite installments with low to no interest rates.

Modernizing B2B Client Delivery
Leading B2B firms are very well aware that their client delivery experience needs to have the same levels of service, responsiveness, transactional ease as any digital consumer experience. Majority (72%) of B2B buyers expect a similar experience on a B2B site as they get on a consumer website (1).

Winning in Mature Markets
Competition is an important facet of business world, and the process of seeking growth is a continuous one. One should never stop trying to win new customers or retain existing ones. After all, competitors are always trying to win your customers over, especially in mature markets.

Putting Customers At The Core of Your Business
Digital Transformation is about developing new capabilities and leveraging new channels to design and deliver a better client experience.

Realizing the Reality of Real Time Payments
Real time payment (RTP) transactions are likely to exceed 300B by 2023, growing at 40% per year worldwide. Financial Institutions need to quickly find their own space in this ecosystem. They must redefine their value proposition and rethink their business models around this phenomenon.

Client Loyalty 2.0
We are on the cusp of a revolution within financial services that will have far-reaching ramifications for the +1 billion unbanked, current models of financial intermediation across entities and borders, and ultimately the very nature of how end-consumers understand financial health. As this understanding held by customers evolves, so too must the operations, services, and visions of providers.

The Tale of Two Countries – Insurance
The pandemic has created unprecedented challenges for the insurance industry. Experiences of the world’s biggest economies (U.S. & China) offer valuable lessons as to where the industry can improve and change in order to better handle similar events in future and build sustainable risk management systems.

Path to Innovation
Innovation has been in vogue for over a decade but the need to be innovative has never been felt as strongly as today. As businesses are learning to thrive under the lasting effects of the pandemic, they need to reinvent products, services and customer experiences to satiate emerging patterns of demand. To truly capitalize on the opportunity, business leaders need to look beyond internal capabilities and embrace a networked model of innovation to drive positive impact.

Reimagining Marketing
The COVID-19 pandemic has re-shaped the landscape for marketers. They are not only forced to cut budgets to save costs, but also face the challenge of keeping up with new emerging customer behaviors. These unprecedented changes call for a broader shift in marketing tactics and investments to successfully navigate the current transformed landscape.

Age of Contactless Mobility
Cities are at a standstill, but they are bound to get moving again. Urban mobility will never be the same, and contactless payments will shape the new normal. Trends are shifting, preferences are being broken, and opportunities abound!

The Path to Decentralized Finance
We are on the cusp of a revolution within financial services that will have far-reaching ramifications for the +1 billion unbanked, current models of financial intermediation across entities and borders, and ultimately the very nature of how end-consumers understand financial health. As this understanding held by customers evolves, so too must the operations, services, and visions of providers.

An Agile Approach to Digitalizing Wholesale Banking
Credit has seen its fair share of ups and downs, from being the crux of financial services, to commoditization and mass distribution, to now being re-engineered. In the realm of Wholesale Credit, a revolution is underway.

Driving Productivity Through Systems Selection
Procurement often involves multiple disparate stakeholders, systems and protocol. This complexity results in increased reliance on inefficient sourcing processes and only partially takes advantage of all the benefits available from supplier competition.

Putting IT Infra Consumers on a Diet
One question seldom asked is “how do I put my (IT infrastructure) customers on a diet?” The demand side is often assumed as a given, and there is with little assessment of (over-) consumption by applications.

Smart Blockchain Contracts: Are We Finally Going Paperless?
Smart contacts offer the potential to facilitate or fully automate processes that are heavily paper-based today, particularly long-winded, expensive legal processes.

The Unbundling of Retail Banking
Not unlike a piece of software, retail banking can be portrayed as a stack comprised of 3 layers, where the complexity of each services can be abstracted into discrete segments and end products.

Binge-Worthy Digital Advice
While the trajectory of ‘digitization’ in financial services is encouraging, there is still significant demand from customers to expand and evolve their digital experience.