The New Normal and Beyond
The adoption of new technologies accelerated digitalization, and, most recently, the shift toward customers, partners and employees working from home, has increased complexity and the burden on IT organizations. Enterprise IT teams face higher risks to stability because of internal and external vulnerabilities as a result.
Legacy IT service management (ITSM) strategies are often inadequate to ensure continued business operations during and after production incidents. While enterprises can try to prevent incidents and to improve their operations so they can recover more quickly, hurdles like functional gaps, poor integration, and unnecessary complexity remain.
Well-grounded CIOs and CTOs focus on the delivery of consistent and stable IT performance. In an environment in which customers’ trust is paramount to success, system stability is essential. While most organizations aim for “four nines” of uptime (99.99%) for critical systems, few can meet that target, and the consequences of falling short can be severe. Outages not only pose reputational risks but also lead to significant revenue loss. According to ITIC’s 2019 “Reliability and Hourly Cost of Downtime Trends Survey,” one-in-three organizations reported that cost of an hour of downtime could reach $1 million to $5million+1
Outages occur across all transaction intensive industries (e.g., tech, FinTech, Telecom). The social network giant Facebook, Inc., which maintains a service availability commitment to 2.3 billion users, experienced several major outages in 2019, with one in March lasting 14 hours2 because of a “server configuration change.” On the financial services side, both Robinhood Markets, Inc. and TD Ameritrade, Inc. had outages in August 2020 in the form of login and latency issues immediately preceding the NYSE’s opening bell. As a result, customers experienced delays in order updates; according to Downdetector, 2,900 users reported problems with Robinhood, while more than 7,000 users reported problems with TD Ameritrade3. Twitter users also reported issues recently with Vanguard and Schwab, as did several other financial services platforms.
These types of outages are not limited to any single cause; some of the most common causes include misconfiguration, right-sizing server workload, and human error. Most notably, the causes of critical issues are often not the applications themselves, but some forgotten underlying shared service like NTP, DNS, and DHCP. Not surprisingly, given the pressures of fast-paced operations, the real root cause is not identified in about 30 percent of critical incidents.
Only as Strong as the Weakest Link
Systems as critical as domain name system (DNS) have been major sources of outages recently. In 2015, DNS went down in several parts of Europe for ~12 hours, resulting in an estimated $32 million in lost revenue for Apple4. In August 2013, Amazon.com was down for approximately 30 minutes, resulting in loss of $66,240 per minute 5. In May 2019, Microsoft experienced a three-hour global outage that affected cloud services (including infra components, an active directory, and an SQL database). Microsoft stated that the outage was caused by “a nameserver delegation change affecting DNS resolution, harming the downstream services” and occurred “during the migration of a legacy DNS system to Azure DNS.”6
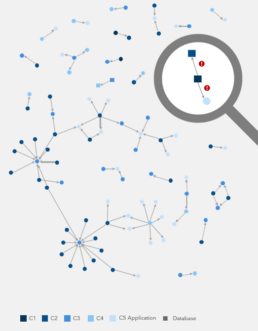
To bolster systems’ availability and resiliency, companies must understand where there are major weaknesses in specific applications but also in all upstream dependencies (Exhibit 1). A holistic, 360- degree approach to stability forensics ensures gaps and vulnerabilities will be revealed. Such a review should cover application architecture standards, business and IT processes, infrastructure capabilities, vendor management, business continuity, and a comprehensive dependency hierarchy review.
A holistic assessment can help drive continuous improvements and is vital to a company’s efforts to uncover systemic challenges that hinder resiliency — insufficient processes, failover capabilities, and technology debt — and to achieve a target-state IT organization.
Exhibit 1. Runtime dependency hierarchy violation assessment
A Myriad of Legacy Challenges
With increasing reliance on IT, organizations are facing several systemic issues like slower incident response times, server capacity exhaustion, and system downtime, leading to technology disruptions and customer-facing service impact. The key for successful mitigation is to first understand the challenges that hinder system performance.
While by no means exhaustive, the items listed below account for most of the technology-related instability and delayed failover times:
1. Tech Debt
2. Failover Automation
3. DevOps Maturity
4. ITSM Data Quality
5. Pervasive Monitoring
The following section will outline common challenges that impact stability. Subsequently, we recommend the most effective remediation strategies to improve system resiliency through improved application architecture, ITSM operations, and process automation, including the adoption of chaos engineering principles.
Tech Debt
The first and perhaps most significant challenge to resiliency is technology debt, that is, the use of deprecated technology, outdated software, subpar architecture, smelly code, and so on. Common culprits range from legacy ERP systems that are too old and too customized to be feasibly upgraded or refactored, over homegrown configuration tools written in legacy languages with few available SMEs, to highly complex monoliths too intricate to extract without incurring significant risk and cost.According to a recent study featured on CNBC, companies spend about $85 billion annually refactoring bad code7. For each CIO, this is money that is spent on maintenance as opposed to investment in new features and products. If funds and resources were deployed effectively, software developers’ expertise could contribute up to $3 trillion to global GDP over the next decade8. The temptation to save money in the near-term results in increased risk, higher costs in the medium term, and further reduction of agility.Unlike application versions and patches, technology debt often goes untracked, which makes it more difficult to address and resolve. The key to resolve technology debt is to first track and replace deprecated infra and app components to avoid architectural workarounds. Additionally, establishing governance to address sub–par engineering (e.g., low code coverage, systems currency) helps in avoiding continued system/code rot.
Failover Automation
Another hurdle in achieving target availability is the lack of sufficiently automated failover capabilities. The key implication is that ITSM teams, rather than failing over immediately, will attempt to fix an issue first; while this can save money and effort, it often results in prolonged outages. In April 2019, an outage at AeroData extended to 40 minutes when redundant systems were not activated, resulting in delay for more than 3,000 flights across 7+ airlines9.
Automated failover provisions are vital for a no-downtime environments. Even though organizations are increasingly moving toward active-active setups, critical applications continue to require manual effort for the failover process, resulting in a pseudo active- active set-up. Any manual failover, active-passive, or delayed service restoration must be eliminated to bolster resiliency.
DevOps Maturity
IT Service Management (ITSM) processes that support critical systems, databases, and underlying infrastructure play a vital role in ensuring resiliency. Hence, process documentation, implementation, and optimization are all necessary to ensure comprehensive alignment of IT processes and services with business goals. Periodic maturity assessments of key stability-impacting processes is necessary for continuous improvement.
ITSM Data Quality
What cannot be measured cannot be changed, so consistent and comprehensive data capture is imperative to ensure target systems’ availability. Configuration Management Databases (CMDBs) are often part of an ITSM solution, providing support for asset management.
Lack of systematic capture of data in CMDB not only hinders a “single source of truth” but also impedes the tracking of IT assets, changes in technology or versions, and maintenance of an evergreen IT organization, all of which are necessary to avoid the stability-impacting considerations discussed above.
Lack of sufficient quantity and quality of data also limits the scope of data-driven planning. For example, capacity planning without in-depth usage data often leads to overestimation.
Pervasive Monitoring
Application monitoring is another essential piece of the puzzle to ensure that infrastructure stays operational and that systems are up and running. Five of ten IT service managers are unsure about the cause of performance problems in production, resulting in a long, manual diagnosis. In fact, 32 percent of IT teams first learn about app performance issues from the users.10
Effective monitoring is not only central to early diagnosis of problem areas but is also important as a regular health check for continuous improvement and for planning future acquisition of equipment.
Exhibit 2. P1 incidents by day and time of the week

Transaction-level monitoring solutions like AppDynamics can deliver end-to-end coverage and early visibility through trends that minimize the risk of outages. AirBnB, which has a service availability commitment to over 150 million users, optimizes its fine-tuning efforts by using NewRelic to accelerate incident response times and to monitor page load times and average user time per page and visit.
Understanding outage trends can help identify process-related gaps (Exhibit 2). IT organizations that do not have a centralized process and operating model for monitoring and reporting but leave it up to the app owners suffer a lack of E2E visibility and long detection times.
Exhibit 3. Key components for a resilient IT organization

1) Application Architecture
Refactoring core apps (e.g., horizontal services, encryption, core business-supporting apps) is the first step for ensuring availability.
a. Reconcile system criticalities with upstream dependencies to eliminate hierarchy violations (e.g., if an application is C1 with 99.99 percent target availability, then all upstream systems must be at least C1 as well)
b. Standardize availability targets. For example, criticality level one is 99.99 percent availability, criticality level two is 99.9 percent availability, and so on
c. Define a clear software-development life cycle. Define a future resiliency strategy (i.e., internal data centers versus cloud-based) and formalize incorporation of resiliency tenets within the software-development life cycle (SDLC)
2) Tech Debt Resolution
Tech debt awareness is a key part of the puzzle, not just for improving stability but also for remediating security vulnerabilities. Organizations should define what constitutes tech debt (e.g., stacks, protocols, use pattern) and identify the main causes (e.g., budget restrictions, lack of documentation and/or testing procedures).Another necessity is the establishment of component currency rules (e.g., N-2) and standards (e.g., code metrics and test coverage), determining end-of-life (EOL) targets for legacy, and defining future strategies and target architecture patterns across the enterprise.
3) Monitoring Optimization
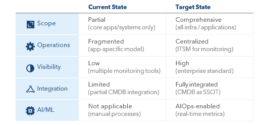
Pervasive and intelligent monitoring is critical for achieving high availability and performance. An effective monitoring ecosystem can reduce and prevent outages through proactive warnings that signal problems before they impact overall performance (Exhibit 4). Key tenets include:
a. Comprehensive monitoring coverage for critical systems
b. Standardized tool deployment for end-to-end visibility
c. Appropriate alert triggers, based on optimal noise-to-alert ratio (too many alerts will clutter notification queues)
d. Artificial intelligence for IT operations (i.e., AIOps) and automation for intelligent monitoring and reporting
Exhibit 4. Performance monitoring target state considerations
4) Engineering for Resiliency
Identification and replacement of outdated components to avoid architectural workarounds is the first step in engineering for resiliency. IT teams must establish governance that proactively addresses sub–par engineering practices like low test case code coverage and system currency to avoid continued system/code rot. In addition, critical systems should demonstrate resilience when deliberate, unpredicted failures in the production system are introduced. Chaos engineering is a proven technique for improving systems resilience:
a. Establish a “chaos monkey” to introduce failure in production
b. Plan simple experiments to start with and gradually ramp up scale
c. Document lessons learnt from early adopters
5) DevSecOps-aligned ITSM
ITSM processes are vital for ensuring that key operational procedures are enforced and stringently governed:
a. Formalize ownership for both primary (i.e., incident, change) and secondary (i.e., capacity, architecture) ITSM processes
b. Measure adherence to ITSM processes (e.g., change, release) and drive continuous improvement
c. Implement DevSecOps-based principles for automation to move from a human-centric to a human-supervised model
6) Service-oriented Business Operations
Designing a service-based operating model that is customer-first is another key part of the puzzle. This approach should promote the use of Agile principles across the entire organization and not just IT, especially when it comes to involving stakeholders from the business. Additional key tenets include:
a. Define service-level requirements (SLRs) and automatically track current vs. target service-level indications (SLIs)
b. Revise, formalize, and institute a service catalog and charge- back mechanism to drive transparency and accountability
7) Evergreening and Maintenance
To maintain evergreen environments, IT teams must establish a formal service strategy practice that sets currency targets at the service level.
A key component of this effort is the categorical embrace the concept of infrastructure-as-code: managing and provisioning computer data centers through machine-readable definition files, rather than physical hardware configuration. In addition, teams should:
a. Leverage external data to track currency (e.g., OSS Index)
b. Validate and refactor homegrown software periodically
c. Establish H/W and S/W currency rules based on criticality
d. Enhance CMDB configuration to improve reporting and monitoring capabilities (e.g., versions, release date)
8) Stability Governance
Stringent governance is required with standardized processes, clearly defined roles and responsibilities, aligned initiatives, and the embrace of continuous improvement. A successful implementation relies on the rollout of organization-wide principles and standards. Most important, however, is a joint governance by the business and technology, to:
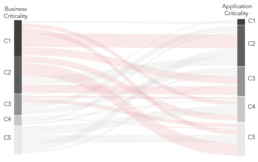
a. Ensure full alignment of goals and resiliency expectations (Exhibit 5)
b. Validate that processes are formally established with clear ownership and documentation (e.g., incident, problem, change, escalations)
c. Establish regular architecture reviews of key initiatives
Exhibit 5. Misalignment of business and IT resiliency expectations
In Closing...
With increasing dependence on technology because of the ongoing C-19 pandemic, it has become critical to ensure systems are running smoothly in support of customers, partners, and employees alike. Periodic in-depth stability assessments can uncover key underlying issues and help companies re-think their processes and respond faster to issues as they arise. For achieving “five nines” system availability, firms should consider:
a. Bolstering application architecture and ongoing maintenance like evergreening to ensure resolution of any architecture and security-related vulnerabilities while maintaining up-to-date IT components.
b. Pervasive monitoring of systems with standardized tools with AIOps-enabled intelligent monitoring to reduce detection times and accelerate resolution of critical incidents.
c. DevSecOps-aligned ITSM processes and service-oriented business operations to enable automated and mature ITSM processes with SLA-driven, high-availability service offerings; and
d. Ongoing stability governance to establish standards, govern processes and data, and enable an enterprise-wide roll-out of playbooks and knowledge-sharing.
1.ITIC. “Hourly Downtime Costs Rise”, 16 May 2019
2.Zarecki, Iris. “Epic Facebook Outage and Its Recent Mini-Echo” Continuity Software, 15 April 2019
3.Major Outages Seen in FS Companies, Downdetector, 2 March 2020
4.“Apple Suffers $32 Million Dollars DNS Outage” Total Uptime, 2015
5.Clay, Kelly. “Amazon.com Goes Down, Loses $66,240 Per Minute” Forbes, 19 August 2013
6.Zarecki, Iris. “19 of the worst IT outages in 2019” Continuity Software, 15 December 2019
7.Avery, Lyal. “The $85 Billion Cost of Bad Code” PullRequest, 30 December 2018
8.Gaybrick, Will. “Tech’s ultimate success: Software developers are now more valuable to companies than money” CNBC, 6 September 2018
9. Zarecki, Iris. “19 of the worst IT outages in 2019” Continuity Software, 15 December 2019
10. Pleasant, Calif. “32 Percent of IT Teams First Learn About Application Performance Issues From Users” ManageEngine, 17 December 2015